
-
Horovod分布式深度学习框架
大小:1.39MB语言:简体中文 类别:国产软件系统:[!--softfj--]
标签:
加载全部内容
EltonWeb框架234KB132人下载Elton的实现参考了koa以及echo,统一中间件的形式,方便定制各类中间件,所有中间件的处理方式都非常简单,如果需要转给下一中间件,则调用Context.Next(),如果当前中间件出错,则返回Error结束调用,如果无需要转至下一中间件,则无需要调用Context.Next()。对于成功返回只需将响应数据赋值Context.Body = 响应数据,由响应中间件将Body转换为相应的响应数据,
下载
Furion Web 开发框架 最新版135.49MB123人下载Furion Web 开发框架 最新版是一个以 .NET 进行开发的非常齐全且兼容性高的一款轻量级框架。这里下载站为您提供Furion Web 开发框架 最新版下载,欢迎您使用这里下载站安装体验!
下载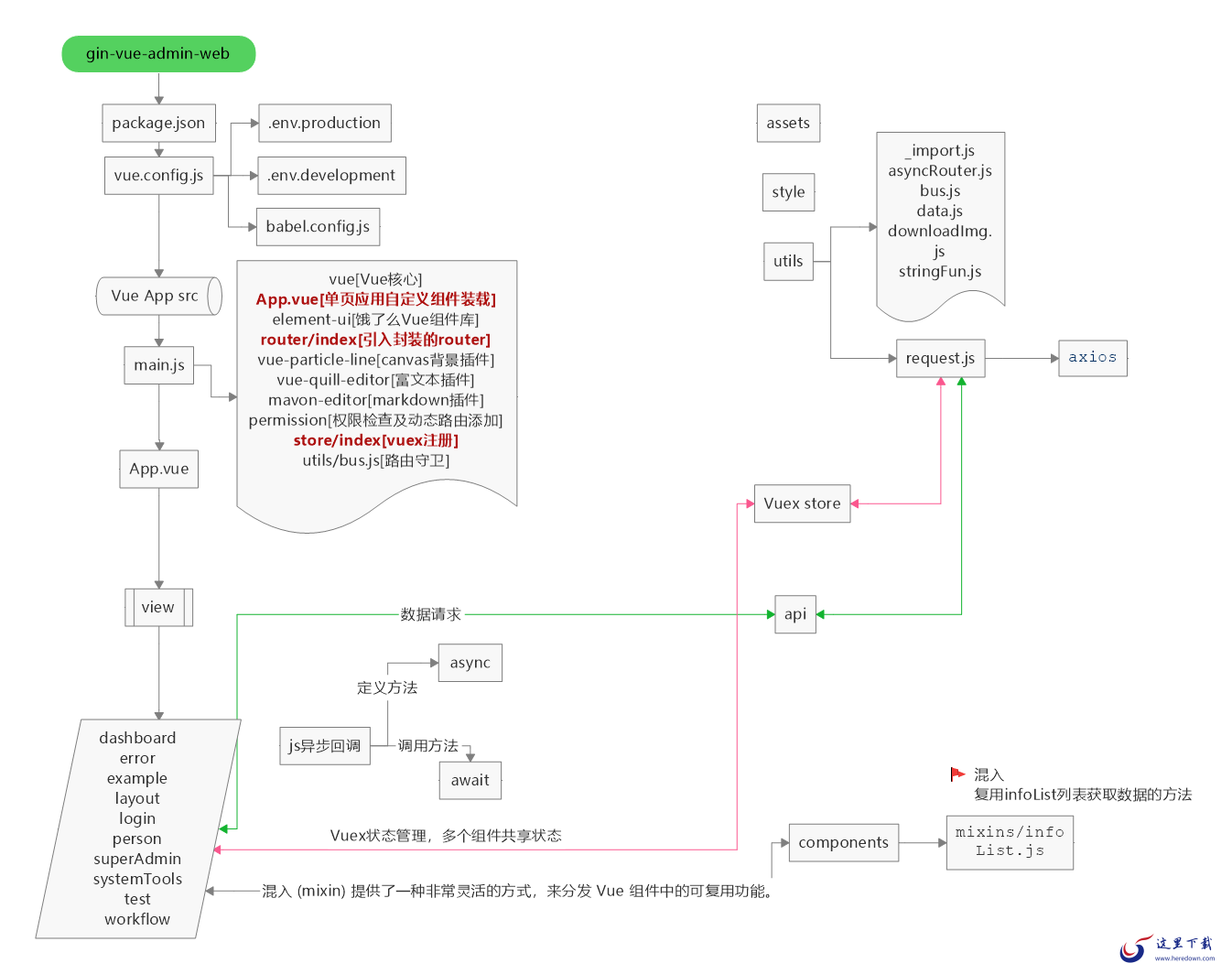
gin-vue-admin 后台管理系统框架 商业版2.31 MB111人下载gin-vue-admin是一个基于gin+vue搭建的后台管理系统框架,集成jwt鉴权,权限管理,动态路由,分页封装,多点登录拦截,资源权限,上传下载,代码生成器,表单生成器,通用工作流等基础功能。
下载L7数据可视分析开发框架13.43MB109人下载L7 是由蚂蚁金服 AntV 数据可视化团队推出的基于 WebGL 的开源大规模地理空间数据可视分析开发框架。L7 中的 L 代表 Location,7 代表世界七大洲,寓意能为全球位置数据提供可视分析的能力。L7 专注数据可视化化表达,通过颜色、大小、纹理,方向,体积等视觉变量设置实现从数据到信息清晰,有效的表达。L7 能够满足常见的地图图表,BI 系统的可视化分析、以及 GIS,交通,电力,国
下载
FastAPI高性能Web框架5.77MB107人下载FastAPI是一个高性能Web框架,用于构建API。FastAPI主要特性:1、快速:非常高的性能,与NodeJS和Go相当2、快速编码:将功能开发速度提高约200%至300%3、更少的错误:减少约40%的人为错误4、直观:强大的编辑器支持,自动补全无处不在,调试时间更少5、简易:旨在易于使用和学习,减少阅读文档的时间。6、简短:减少代码重复。7、稳健:获取可用于生产环境的代码,具有自动交互式文
下载Taro多端统一开发框架4.16MB107人下载Taro框架是由京东 - 凹凸实验室打造的一套遵循 React 语法规范的多端统一开发框架。现如今市面上端的形态多种多样,Web、App 端(React Native)、微信小程序等各种端大行其道,当业务要求同时在不同的端都要求有所表现的时候,针对不同的端去编写多套代码的成本显然非常高,这时候只编写一套代码就能够适配到多端的能力就显得极为需要。使用 Taro,我们可以只书写一套代码,再通过 Tar
下载
AdonisWeb框架327KB107人下载Adonisjs是一个Node.js Web框架,专注于易用性与速度。它甚至是一个全栈Web框架,解决了许多Web开发难题,提供了一个干净稳定的API,用于构建Web应用和微服务,或者用于TDD(测试驱动开发)。Adonisjs特色:类型安全类型安全被嵌入到框架中,并对TypeScript提供一流的支持。无需安装任何额外的构建工具,TypeScript只需与AdonisJS一起工作。可扩展性无需在
下载
Foundation响应式前端框架11.44MB106人下载Foundation响应式前端框架是一个易用、强大而且灵活的框架,用于构建基于任何设备上的 Web 应用。提供多种 Web 上的 UI 组件,如表单、按钮、Tabs 等等。Foundation 是世界上比较先进的响应式前端框架。使用 Foundation 快速从原型到生产、构建可在任何类型设备上运行的站点或应用程序。包括一个完全可定制的响应式网格、一个大型 Sass 混合库、常用的 JavaScr
下载
BootstrapBlazorUI框架8.83MB106人下载BootstrapBlazor UI框架是一个使用 .NET 生成交互式客户端 Web UI 的框架:1、使用 C# 代替 JavaScript 来创建丰富的交互式 UI。2、共享使用 .NET 编写的服务器端和客户端应用逻辑。3、将 UI 呈现为 HTML 和 CSS,以支持众多浏览器,其中包括移动浏览器。使用 .NET 进行客户端 Web 开发可提供以下优势:1、使用 C# 代替 JavaSc
下载Taro多端统一开发框架 正式版5.18MB106人下载 Taro框架是由京东 - 凹凸实验室打造的一套遵循 React 语法规范的多端统一开发框架。现如今市面上端的形态多种多样,Web、App 端(React Native)、微信小程序等各种端大行其道,当业务要求同时在不同的端都要求有所表现的时候,针对不同的端去编写多套代码的成本显然非常高,这时候只编写一套代码就能够适配到多端的能力就显得极为需要。
下载 AdonisWeb框架
AdonisWeb框架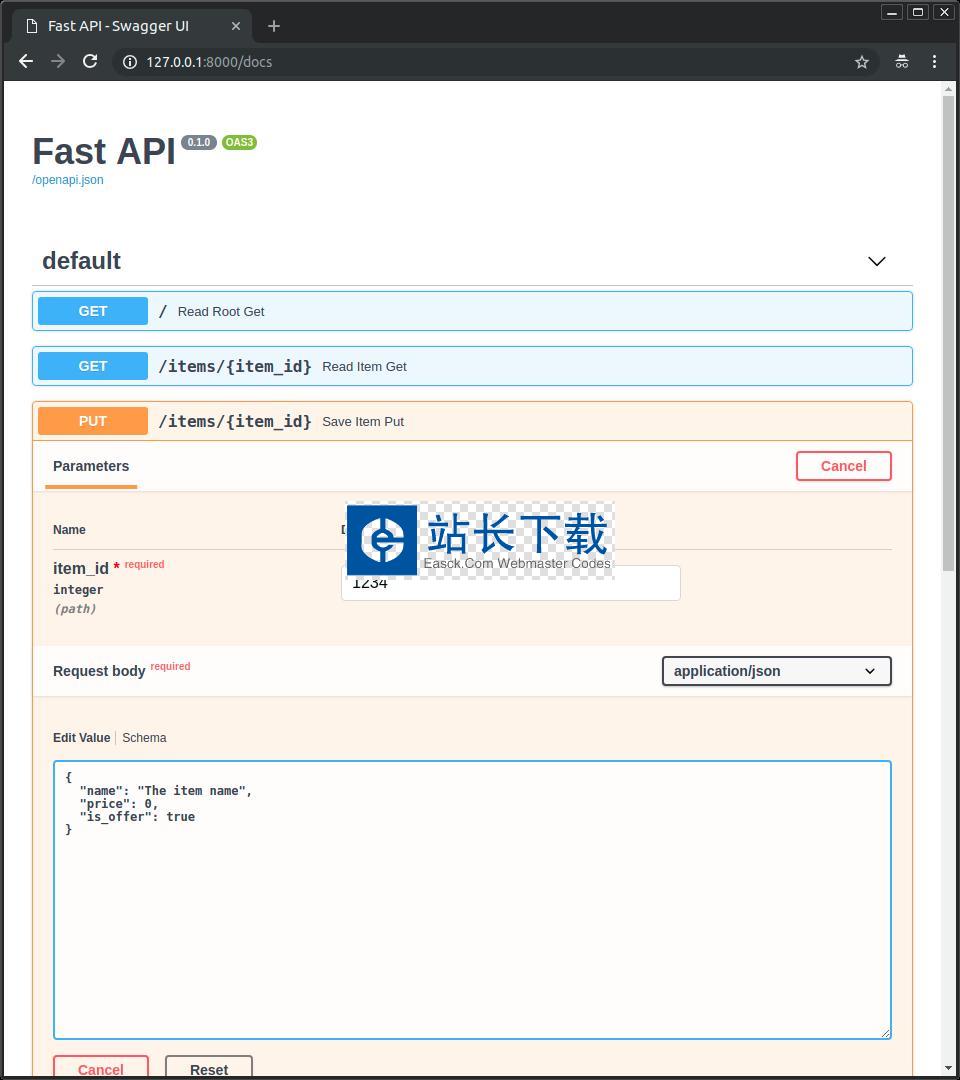 FastAPI高性能Web框架 正式版
FastAPI高性能Web框架 正式版 植物大战僵尸攻略教程
植物大战僵尸攻略教程 植物大战僵尸手游下载
植物大战僵尸手游下载 瞩目视频会议教程专辑
瞩目视频会议教程专辑 瞩目视频会议下载
瞩目视频会议下载 2345安全卫士教程合集
2345安全卫士教程合集 2345安全卫士下载专辑
2345安全卫士下载专辑 2345好压教程合集
2345好压教程合集 爱奇艺视频教程合集
爱奇艺视频教程合集